A Brief History of Video Quality Measurement: From PSNR to VMAF and Beyond


In recent decades, video quality measurement (VQM) has been a heavily researched topic. VQM is used in various applications such as comparing video quality, configuring and benchmarking encoders, 24/7 quality monitoring, A/B testing, and standardization. There are different types of VQM, and based on the availability of the source signal, it can be classified into full-reference VQM and no-reference VQM.
Full-reference VQM (FR-VQM, Figure 1a) uses pixel values from both the receiver side (after decoding) and the source/input signal side. By comparing these values, an accurate evaluation of the received signal can be obtained. Many FR-VQM metrics have been proposed over the years, as detailed in the following sections.
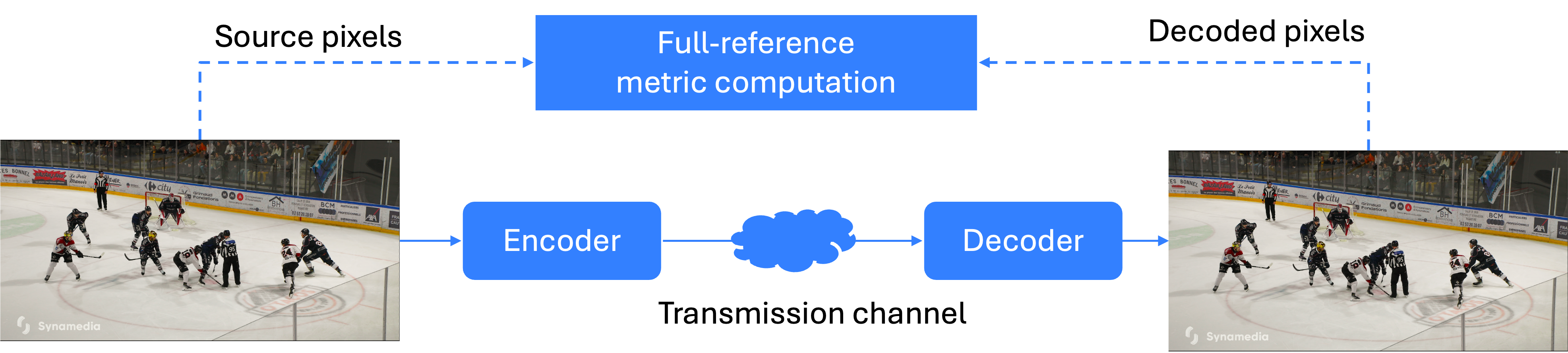
Figure 1a. Full-reference VQ comparison and metric computation: comparing the decoded file to its source signal.
No-reference VQM (NR-VQM, Figure 1b) does not require access to the source signal. A video quality score can be calculated at different points during distribution, based on an overall assessment of video quality without referring to the original video. While this method increases flexibility and allows for VQ scoring regardless of the source quality, NR-VQM metrics are generally less accurate than FR-VQM metrics.
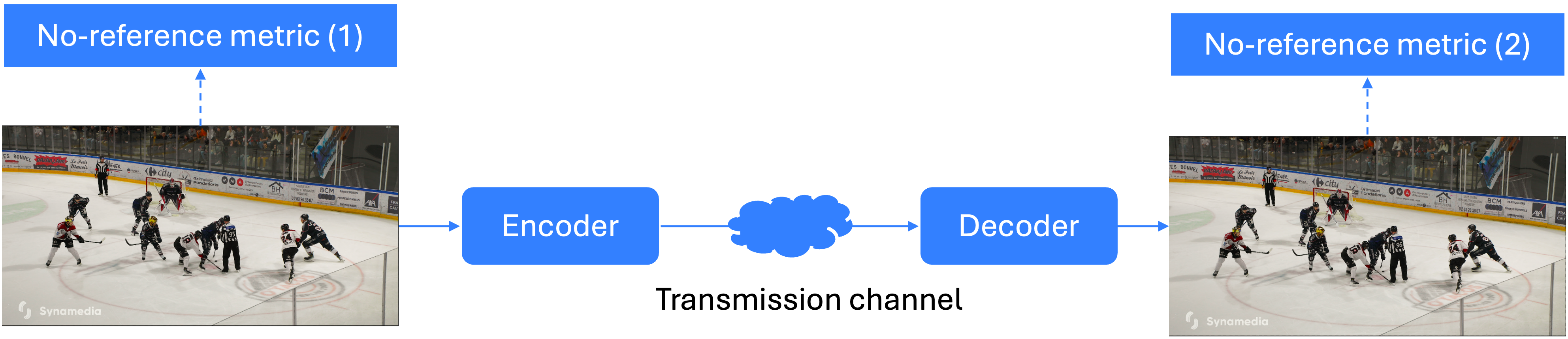
Figure 1b: No-reference VQM computation at different points in the distribution chain.
Several NR metrics have been proposed, each offering varying degrees of accuracy. Examples include BRISQUE, NIQE, and NR-VMAF [1]. However, NR-VQM remains a challenging area, and the accuracy of these metrics often depends on the specific application or type of distortion being measured [2].
In many applications, traditional L2-norm-based metrics such as mean squared error (MSE) and peak signal-to-noise ratio (PSNR) are still in use. These metrics are easy to calculate and provide a rough indication of quality differences. However, their lower accuracy limits their applicability in modern video quality assessment [3].
A popular metric with higher accuracy is Structural Similarity (SSIM) [4], which computes and combines luminance, saturation, and structural similarity across local neighborhoods in the video frames. SSIM was later extended into multiscale SSIM (MS-SSIM), which calculates SSIM at several resolutions to improve accuracy, though this also increases computational complexity [5]. A comprehensive overview of SSIM, MS-SSIM, their implementations, and recommended practices is provided in [6].
Other metrics based on human visual system models have been proposed, such as the Detail Loss Measure (DLM) [7]. Combined with natural scene statistics, DLM led to the development of the Visual Information Fidelity (VIF) criterion [8].
In 2016, the strengths of multiple metrics were combined into the Video Multimethod Assessment Fusion (VMAF) metric, introduced by Netflix [9]. VMAF produces quality scores by taking into account both quantization artifacts (such as blockiness) and scaling artifacts (such as blurriness from upscaling). This makes VMAF particularly well-suited for comparing video quality across multiple ABR renditions and optimizing ABR ladders.
VMAF uses a scale from 0 to 100, which is easy to interpret and maps intuitively to Mean Opinion Scores (MOS), ranging from poor to excellent video quality. Due to its advantages and open-source availability [10], VMAF has become a de facto industry standard for VQM in video-on-demand environments.
 2a: VMAF= 96.7 |
 2b: VMAF= 81.0 |
 2c: VMAF= 62.1 |
 2d: VMAF= 42.1 |
Figures 2a-d: Various VMAF scores illustrating differences in video quality across AVC encodes.
Since its introduction, several VMAF extensions, improvements [11], and approximations have been developed to increase its utility. VMAF has been deployed in encoder optimization, shot-based encoding [12], and even in no-reference VQM [1]. One key improvement is the “no enhancement gain” model (VMAF-NEG), which accounts for the potential effects of sharpening or image manipulation [13]
Despite its strengths, VMAF has several limitations. For instance, it does not consider color (chrominance) channels, its temporal features are relatively weak, and no publicly available model exists for high dynamic range (HDR) video. To address banding artifacts, Netflix developed the CAMBI detector, which complements VMAF by assigning a score to regions affected by banding [14].
One of the most significant challenges with VMAF, particularly for live video or real-time applications, is its computational complexity. Certain underlying features, such as VIF, are especially time-consuming to compute. While approaches based on deep neural networks (DNNs) offer high accuracy, their extreme complexity makes them impractical for live environments.
In recent years, work by Meta and other researchers has focused on simplifying and unifying VQM features. For example, the FUNQUE metric [15][16] offers high accuracy at lower computational complexity. Additionally, the XPSNR metric [17] has emerged as a low-complexity alternative for high-resolution video quality assessment.
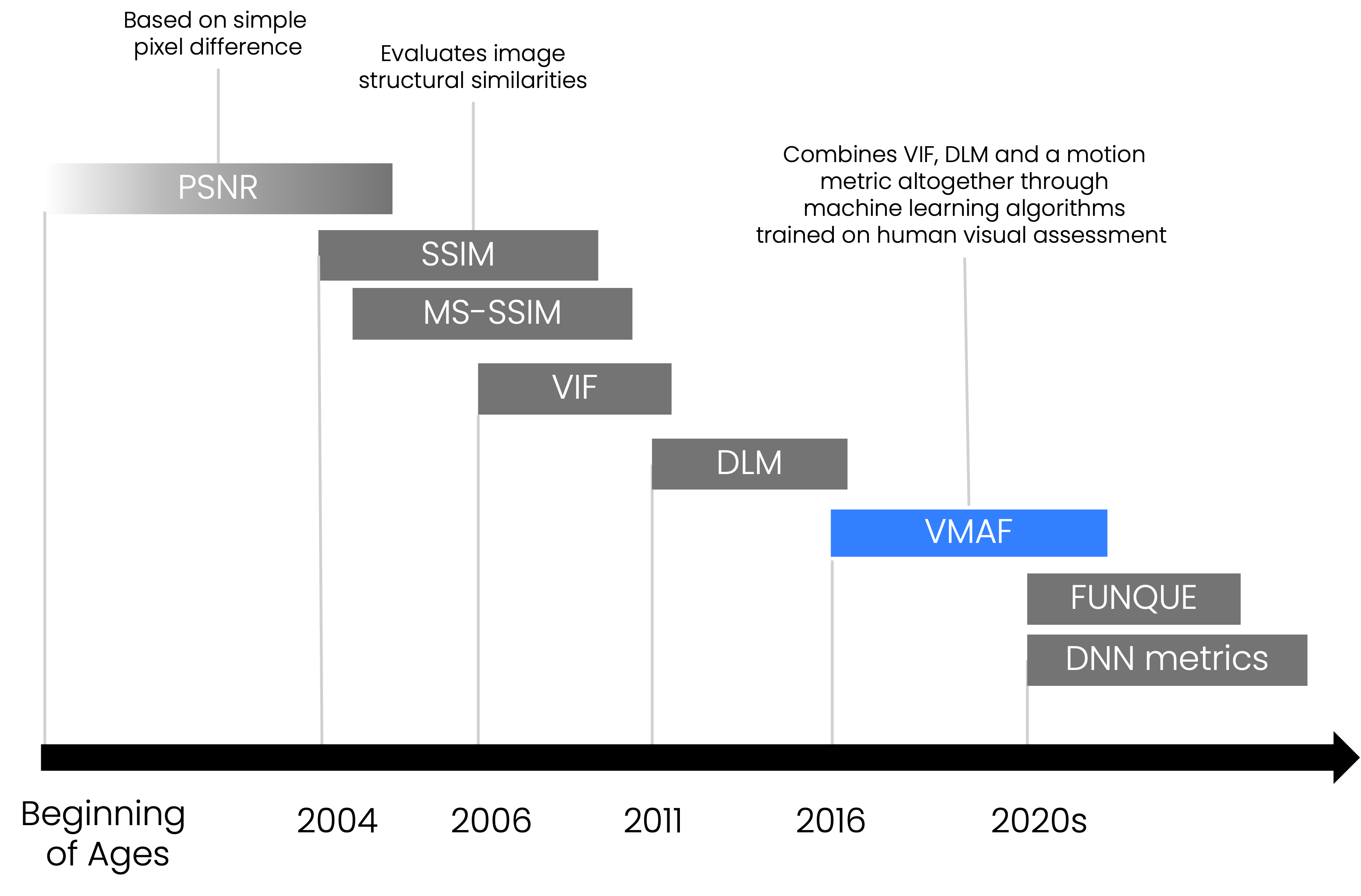
Figure 3: Overview of milestones in FR-VQM metric development over the past decades.
Although both VMAF and FUNQUE have merits, the computational cost of VQM remains substantial—sometimes even comparable to video compression itself. For most video-on-demand applications, this CPU and financial cost is acceptable, but in live environments where cost and CPU cycles are constrained, more efficient approaches are necessary.
This is why Synamedia is introducing pVMAF, a VMAF predictor specifically designed for live video encoding applications. In Part 2 of this tech blog series, we will dive deeper into pVMAF, exploring its accuracy and how it significantly reduces computational requirements for real-time video quality assessments.
[1] A. De Decker, J. De Cock, P. Lambert and G. V. Wallendael, “No-Reference VMAF: A Deep Neural Network-Based Approach to Blind Video Quality Assessment,” in IEEE Transactions on Broadcasting, vol. 70, no. 3, pp. 844-861, Sept. 2024, doi: 10.1109/TBC.2024.3399479.
[2] M. H. Pinson, “Why No Reference Metrics for Image and Video Quality Lack Accuracy and Reproducibility,” in IEEE Transactions on Broadcasting, vol. 69, no. 1, pp. 97-117, March 2023, doi: 10.1109/TBC.2022.3191059.
[3] Z. Wang and A. C. Bovik, “Mean squared error: Love it or leave it? A new look at Signal Fidelity Measures,” in IEEE Signal Processing Magazine, vol. 26, no. 1, pp. 98-117, Jan. 2009, doi: 10.1109/MSP.2008.930649.
[4] Zhou Wang, A. C. Bovik, H. R. Sheikh and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” in IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600-612, April 2004, doi: 10.1109/TIP.2003.819861.
[5] Z. Wang, E. P. Simoncelli and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, Pacific Grove, CA, USA, 2003, pp. 1398-1402 Vol.2, doi: 10.1109/ACSSC.2003.1292216.
[6] A. K. Venkataramanan, C. Wu, A. C. Bovik, I. Katsavounidis and Z. Shahid, “A Hitchhiker’s Guide to Structural Similarity,” in IEEE Access, vol. 9, pp. 28872-28896, 2021, doi: 10.1109/ACCESS.2021.3056504.
[7] S. Li, F. Zhang, L. Ma and K. N. Ngan, “Image Quality Assessment by Separately Evaluating Detail Losses and Additive Impairments,” in IEEE Transactions on Multimedia, vol. 13, no. 5, pp. 935-949, Oct. 2011, doi: 10.1109/TMM.2011.2152382.
[8] H. R. Sheikh and A. C. Bovik, “Image information and visual quality,” in IEEE Transactions on Image Processing, vol. 15, no. 2, pp. 430-444, Feb. 2006, doi: 10.1109/TIP.2005.859378.
[9] Zhi Li, Anne Aaron, Ioannis Katsavounidis, Anush Moorthy and Megha Manohara, “Toward A Practical Perceptual Video Quality Metric”, Netflix Technology Blog, June 2016.
[10] Source code for VMAF – Video Multi-Method Assessment Fusion, available through https://github.com/Netflix/vmaf.
[11] F. Zhang, A. Katsenou, C. Bampis, L. Krasula, Z. Li and D. Bull, “Enhancing VMAF through New Feature Integration and Model Combination,” 2021 Picture Coding Symposium (PCS), Bristol, United Kingdom, 2021, pp. 1-5, doi: 10.1109/PCS50896.2021.9477458.
[12] Megha Manohara, Anush Moorthy, Jan De Cock, Ioannis Katsavounidis and Anne Aaron, “Optimized shot-based encodes: Now Streaming!”, Netflix Technology Blog, March 2018.
[13] Zhi Li, Kyle Swanson, Christos Bampis, Lukáš Krasula and Anne Aaron, “Toward a Better Quality Metric for the Video Community”, Netflix Technology Blog, December 2020.
[14] Joel Sole, Mariana Afonso, Lukas Krasula, Zhi Li, and Pulkit Tandon, “CAMBI, a banding artifact detector”, Netflix Technology Blog, October 2021
[15] K. Venkataramanan, C. Stejerean and A. C. Bovik, “FUNQUE: Fusion of Unified Quality Evaluators,” 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 2022, pp. 2147-2151, doi: 10.1109/ICIP46576.2022.9897312.
[16] A. K. Venkataramanan, C. Stejerean, I. Katsavounidis and A. C. Bovik, “One Transform to Compute Them All: Efficient Fusion-Based Full-Reference Video Quality Assessment,” in IEEE Transactions on Image Processing, vol. 33, pp. 509-524, 2024, doi: 10.1109/TIP.2023.3345227.
[17] C. R. Helmrich, M. Siekmann, S. Becker, S. Bosse, D. Marpe and T. Wiegand, “Xpsnr: A Low-Complexity Extension of The Perceptually Weighted Peak Signal-To-Noise Ratio For High-Resolution Video Quality Assessment,” 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2727-2731, doi: 10.1109/ICASSP40776.2020.9054089.
Jan leads the compression team at Synamedia and is responsible for the company’s codec development operations. Having spent his entire career in the compression space, most recently as Manager of Video and Image Encoding at Netflix, Jan is one of the industry’s foremost encoding experts.
Prior to his role at Netflix, Jan was Assistant Professor in the Department of Electronics and Information Systems at Ghent University in Belgium.
Jan holds a PhD in Engineering from Ghent University in Belgium. He was general co-chair of the 2018 Picture Coding Symposium (PCS), co-organizer of the 1st AOMedia Research Symposium in 2019, and has been a presenter and speaker at a wide range of international conferences.





Sign up to Synamedia events and news